1 Introduction
The Kolmogorov–Smirnov (KS) test is a nonparametric, univariate statistical test designed to assess whether a sample of data is consistent with a given probability distribution (or, in the two-sample case, whether the two samples came from the same underlying distribution). First described by Kolmogorov and Smirnov in a series of papers (Kolmogorov 1933a,b; Smirnov 1936, 1937, 1939, 1944, 1948), the KS test is a popular goodness-of-fit test that has found use across a wide variety of scientific disciplines, including neuroscience (Atasoy et al. 2017), climatology (Chiang et al. 2018), robotics (Hahne et al. 2018), epidemiology (Wong and Collins 2020), and cell biology (Kaczanowska et al. 2021).
Due to its popularity, several multivariate extensions of the KS test have been described in literature. Justel et al. (1997) proposed a multivariate test based on Rosenblatt’s transformation, which reduces to the KS test in the univariate case. While the test statistic is distribution-free, it is difficult to compute in more than two dimensions, and an approximate test with reduced power must be used instead. Furthermore, the test is only applicable in the one-sample case. Heuchenne and Mordant (2022) proposed to use the Hilbert space-filling curve to define an ordering in \(\mathbb{R}^{2}\). The preimage of both samples is computed under the space-filling curve map, and the two-sample KS test is performed on the preimages. While it is theoretically possible to extend this approach to higher dimensions, the authors note that this would be computationally challenging and leave it as an open problem. Naaman (2021) derived a multivariate extension of the DKW inequality and used it to provide estimates of the tail properties of the asymptotic distribution of the KS test statistic in multiple dimensions. While an important theoretical result, it is of limited practical use absent a method for computing exact \(p\)-values.
Peacock (1983) proposed a test which addresses the fact that there are multiple ways to order points in higher dimensions, and thus multiple ways of defining a cumulative distribution function. In one dimension, probability density can be integrated from left to right, resulting in the canonical CDF \(P(X<x)\); or from right to left, resulting in the survival function \(P(X>x)\). However, since \(P(X<x)=1-P(X>x)\) (for continuous random variables), the KS test statistic is independent of this choice. In two dimensions, there are four ways of ordering points, and thus four possible cumulative distribution functions: \(P(X<x,Y<y)\), \(P(X>x,Y<y)\), \(P(X<x,Y>y)\), and \(P(X>x,Y>y)\). Since any three of these are independent of one another, the KS test statistic will not be independent of which ordering is chosen. To address this, Peacock (1983) proposed to compute a KS statistic using each possible cumulative distribution function, and to take the test statistic to be the maximum of those.
Peacock (1983) suggested that for a sample \((X_{1},Y_{1}),\dots,(X_{n},Y_{n})\), each of the four KS statistics should be maximized over the set of all coordinate-wise combinations \(\{(X_{i},Y_{j}):1\leq i,j\leq n\}\). The complexity of computing Peacock’s test statistic thus scales cubically with sample size, which is expensive and can become intractable for large sample sizes. Fasano and Franceschini (1987) proposed a simple change to Peacock’s test: instead of maximizing each KS statistic over all coordinate-wise combinations of points in the sample, the statistics should be maximized over just the points in the sample itself. This slight change greatly reduces the computational complexity of the test while maintaining a similar power across a variety of alternatives (Fasano and Franceschini 1987; Lopes et al. 2007). Fasano and Franceschini (1987) proposed both a one-sample and two-sample version of their test, although we focus on the two-sample test here.
In this article we present the fasano.franceschini.test package, an R implementation of the two-sample Fasano–Franceschini test. Our implementation can be applied to continuous, discrete, or mixed datasets of any size and of any dimension. We first introduce the test by detailing how the test statistic is computed, how it can be computed efficiently, and how \(p\)-values can be computed. We then describe the package structure and provide several basic examples illustrating its usage. We conclude by comparing the package to three other CRAN packages implementing multivariate two-sample goodness-of-fit tests.
2 Fasano–Franceschini test
2.1 Two-sample test statistic
Let \(\mathbf{X}=(\mathbf{X}_{1},\dots,\mathbf{X}_{n_{1}})\) and \(\mathbf{Y}=(\mathbf{Y}_{1},\dots,\mathbf{Y}_{n_{2}})\) be samples of i.i.d. \(d\)-dimensional random vectors drawn from unknown distributions \(F_{1}\) and \(F_{2}\), respectively. The two-sample Fasano–Franceschini test evaluates the null hypothesis \[H_{0}:F_{1}=F_{2}\] against the alternative \[H_{1}:F_{1}\neq F_{2}.\] In their original paper, Fasano and Franceschini (1987) only considered two- and three-dimensional random vectors, although their test naturally extends to arbitrary dimensions as follows.
For \(\mathbf{x}\in\mathbb{R}^{d}\), we define the \(i\)th open orthant with origin \(\mathbf{x}\) as \[\mathcal{O}_{i}(\mathbf{x})=\left\{\mathbf{y}\in\mathbb{R}^{d}\,\rvert\,\mathbf{e}_{ij}(\mathbf{y}_{j}-\mathbf{x}_{j})>0,\;j=1,\dots,d\right\}\] where \(\mathbf{e}_{i}\in\{-1,1\}^{d}\) is a length \(d\) combination of \(\pm 1\). For example, in two dimensions, the four combinations \(\mathbf{e}_{1}=(1,1)\), \(\mathbf{e}_{2}=(-1,1)\), \(\mathbf{e}_{3}=(-1,-1)\), and \(\mathbf{e}_{4}=(1,-1)\) correspond to quadrants one through four in the plane, respectively. In general there are \(2^{d}\) such combinations, corresponding to the \(2^{d}\) orthants that divide \(\mathbb{R}^{d}\). Using the indicator function \[I_{j}(\mathbf{x}\,\rvert\,\mathbf{y})= \begin{cases} 1,\hfill&\mathbf{x}\in\mathcal{O}_{j}(\mathbf{y})\\ 0,\hfill&\mathbf{x}\notin\mathcal{O}_{j}(\mathbf{y}) \end{cases}\] we define \[\label{eq:diff} D(\mathbf{p}\,\rvert\,\mathbf{X},\mathbf{Y})=\max_{1\leq j\leq 2^{d}}\left|\frac{1}{n_{1}}\sum_{k=1}^{n_{1}}I_{j}\left(\mathbf{X}_{k}\,\rvert\,\mathbf{p}\right)-\frac{1}{n_{2}}\sum_{k=1}^{n_{2}}I_{j}\left(\mathbf{Y}_{k}\,\rvert\,\mathbf{p}\right)\right|.~~~~~(1)\] This is similar to the distance used in the two-sample KS test, but takes into account all possible ways of ordering points in \(\mathbb{R}^{d}\). Note that this function does not depend on the enumeration of the orthants. Maximizing \(D\) over each sample separately leads to the difference statistics \[D_{1}(\mathbf{X},\mathbf{Y})=\max_{1\leq i\leq n_{1}}D(\mathbf{X}_{i}\,\rvert\,\mathbf{X},\mathbf{Y})\] and \[D_{2}(\mathbf{X},\mathbf{Y})=\max_{1\leq i\leq n_{2}}D(\mathbf{Y}_{i}\,\rvert\,\mathbf{X},\mathbf{Y}).\] The two-sample Fasano–Franceschini test statistic, as originally defined by Fasano and Franceschini (1987), is the average of the difference statistics scaled by the sample sizes: \[\label{eq:ff_stat} \mathcal{D}_{0}(\mathbf{X},\mathbf{Y})=\sqrt{\frac{n_{1}n_{2}}{n_{1}+n_{2}}}\left(\frac{D_{1}(\mathbf{X},\mathbf{Y})+D_{2}(\mathbf{X},\mathbf{Y})}{2}\right).~~~~~(2)\] This test statistic is discrete, but in general is not integer-valued. Note that \[n_{1}n_{2}D(\mathbf{p}\,\rvert\,\mathbf{X},\mathbf{Y})=\max_{1\leq j\leq 2^{d}}\left|n_{2}\sum_{k=1}^{n_{1}}I_{j}\left(\mathbf{X}_{k}\,\rvert\,\mathbf{p}\right)-n_{1}\sum_{k=1}^{n_{2}}I_{j}\left(\mathbf{Y}_{k}\,\rvert\,\mathbf{p}\right)\right|\in\mathbb{Z},\] and thus \[n_{1}n_{2}D_{i}(\mathbf{X},\mathbf{Y})\in\mathbb{Z},\;i\in\{1,2\}.\] Let \[C_{n_{1},n_{2}}=2\sqrt{n_{1}n_{2}(n_{1}+n_{2})}.\] Then \[\begin{aligned} C_{n_{1},n_{2}}\mathcal{D}_{0}(\mathbf{X},\mathbf{Y})&=2\sqrt{n_{1}n_{2}(n_{1}+n_{2})}\sqrt{\frac{n_{1}n_{2}}{n_{1}+n_{2}}}\left(\frac{D_{1}(\mathbf{X},\mathbf{Y})+D_{2}(\mathbf{X},\mathbf{Y})}{2}\right)\\&=n_{1}n_{2}(D_{1}(\mathbf{X},\mathbf{Y})+D_{2}(\mathbf{X},\mathbf{Y}))\in\mathbb{Z}. \end{aligned}\] To avoid comparing floating point numbers, it is preferable for the test statistic to be integer-valued, and thus we use \[\mathcal{D}(\mathbf{X},\mathbf{Y})=C_{n_{1},n_{2}}\mathcal{D}_{0}(\mathbf{X},\mathbf{Y}) \label{eq:test_stat} ~~~~~(3)\] as our test statistic. As will be shown, the \(p\)-value of the test is independent of scalar rescaling of the test statistic.
2.2 Computational complexity
The bulk of the time required to compute the test statistic in (3) is spent evaluating sums of the form \[\sum_{\mathbf{x}\in S}I_{j}\left(\mathbf{x}\,\rvert\,\mathbf{y}\right),\] which count the number of points in a set \(S\) that lie in a given \(d\)-dimensional region. The simplest approach to computing such sums is brute force, where every point \(\mathbf{x}\in S\) is checked independently. The orthant a point lies in can be determined using \(d\) binary checks, resulting in a time complexity of \(O(N^{2})\), where \(N=\max(n_{1},n_{2})\), to evaluate (3) for fixed \(d\).
Alternatively, we can consider each sum as a single query rather than a sequence of independent ones. Specifically, both sums in (1) are orthogonal range counting queries, which ask how many points in a set \(S\subset\mathbb{R}^{d}\) lie in an axis-aligned box \((x_{1},x_{1}')\times\dots \times(x_{d},x_{d}')\). Range counting is an important problem in the field of computational geometry, and as such a variety of data structures have been described to provide efficient solutions (Berg et al. 2008). One solution, first introduced by Bentley (1979), is a multi-layer binary search tree termed a range tree. Other slightly more efficient data structures have been proposed for range counting, but range trees are well suited for our purposes, particularly because their construction scales easily to arbitrary dimensions (Bentley 1979; Berg et al. 2008).
A range tree can be constructed on a set of \(n\) points in \(d\)-dimensional space using \(O(n\log^{d-1}n)\) space in \(O(n\log^{d-1}n)\) time. The number of points that lie in an axis-aligned box can be reported in \(O(\log^{d}n)\) time, and this time can be further reduced to \(O(\log^{d-1}n)\) when \(d>1\) using fractional cascading (Berg et al. 2008). To compute (3), we construct one range tree for each of the two samples, and then query each tree \(2^{d}\) times. Thus the total time complexity to compute the test statistic using range trees for fixed \(d\) is \(O(N\log^{d-1}N)\), where \(N=\max(n_{1},n_{2})\).
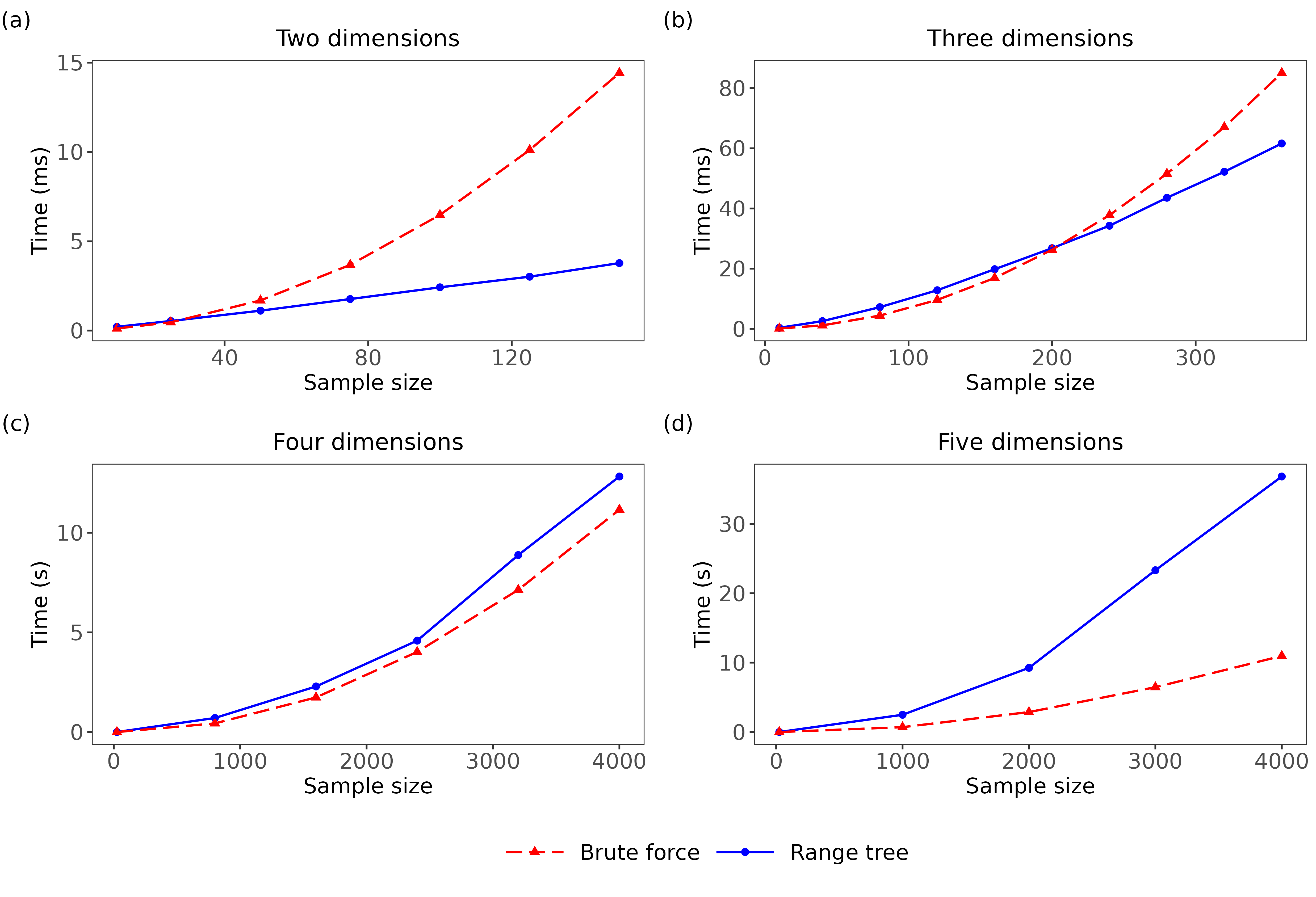
As the range tree method has a better asymptotic time complexity, we expect it to outperform the brute force method for larger sample sizes. However, for smaller sample sizes, the cost of building the range trees can outweigh the benefit gained by more efficient querying. As exact computation times can vary depending on the geometry of the samples, it is not possible to determine in general when one method will outperform the other. Despite this, we sought to establish rough benchmarks. Drawing equal sized samples from multivariate standard normal distributions, we sought to determine the sample size \(N^{*}\) at which the range tree method becomes more efficient than the brute force method (Figure 2). For \(d=2\), \(N^{*}\approx 25\); for \(d=3\), \(N^{*}\approx 200\); for \(d=4,5\), and presumably all higher dimensions, \(N^{*}>4000\). Based on these benchmarking results, our package automatically selects which of the two methods is likely faster based on the dimension and samples sizes of the supplied data. If users are interested in performing more precise benchmarking for their specific dataset, the argument nPermute can be set equal to \(0\), which bypasses the permutation test and only computes the test statistic.
2.3 Significance testing
To the best of our knowledge, no results have been published concerning the distribution of the Fasano–Franceschini test statistic. Any analysis would likely be complicated by the fact that, unlike the KS test statistic, the Fasano–Franceschini test statistic is not distribution free (Fasano and Franceschini 1987). In their original paper, Fasano and Franceschini (1987) did not attempt any analytical analysis and instead performed simulations to estimate critical values of their test statistic for various two- and three-dimensional distributions. By fitting a curve to their results, Press et al. (2007) proposed an explicit formula for \(p\)-values in the two-dimensional case. However, this formula is only approximate, and its accuracy degrades as sample sizes decrease or the true \(p\)-value becomes large (greater than \(0.2\)). While this would still allow a simple rejection decision at any common significance level, it is sometimes useful to quantify large \(p\)-values more exactly (such as if one was to do a cross-study concordance analysis comparing \(p\)-values between studies as in Ness-Cohn et al. (2020)). Effort could be made to improve this approximation, however it is still only valid in two dimensions, and thus an alternative method would be needed in higher dimensions.
To ensure the broadest applicability of the test, we assess significance using a permutation test. Let \(\mathbf{Z}=(\mathbf{Z}_{1},\dots,\mathbf{Z}_{N})\) be defined by \[\mathbf{Z}_{i}=\begin{cases} \mathbf{X}_{i},&1\leq i\leq n_{1}\\ \mathbf{Y}_{i-n_{1}},&n_{1}+1\leq i\leq N \end{cases}\] where \(N=n_{1}+n_{2}\). The test statistic in (3) can then be written as \[\mathcal{D}(\mathbf{Z})=\mathcal{D}(\mathbf{X},\mathbf{Y}).\] Denote the symmetric group on \(\{1,\dots,n\}\subset\mathbb{N}\) by \(S_{n}\). For \(\mathbf{x}=(\mathbf{x}_{1},\dots,\mathbf{x}_{n})\) and \(\sigma\in S_{n}\), define \[\mathbf{x}_{\sigma}=(\mathbf{x}_{\sigma(1)},\dots,\mathbf{x}_{\sigma(n)}).\] Under the null hypothesis, \(\mathbf{X}\) and \(\mathbf{Y}\) were drawn from the same distribution, and thus the elements of \(\mathbf{Z}\) are exchangeable. We can therefore compute the permutation test p-value \[p=\frac{\sum_{\sigma\in S_{N}}I(\mathcal{D}(\mathbf{Z}_{\sigma})\geq\mathcal{D}(\mathbf{Z}))}{N!}\] where \(I\) denotes the indicator function (Hemerik and Goeman 2018; Ramdas et al. 2022). As it is generally infeasible to iterate over all \(N!\) permutations, we can instead consider for \(M\in\mathbb{N}\) \[p_{M}=\frac{1+\sum_{m=1}^{M}I(\mathcal{D}(\mathbf{Z}_{\sigma_{m}})\geq\mathcal{D}(\mathbf{Z}))}{1+M}\] where \(\sigma_{1},\dots,\sigma_{M}\) are independent permutations drawn uniformly from \(S_{N}\). This \(p\)-value is valid, as under the null hypothesis \[\mathbb{P}(p_{m}\leq\alpha)\leq\alpha \ \forall\alpha\in[0,1].\] Moreover, \(p_{M}\to p\) almost surely. These results hold for any sampling distributions (continuous, discrete, or mixed) and any valid test statistic (Hemerik and Goeman 2018; Ramdas et al. 2022).
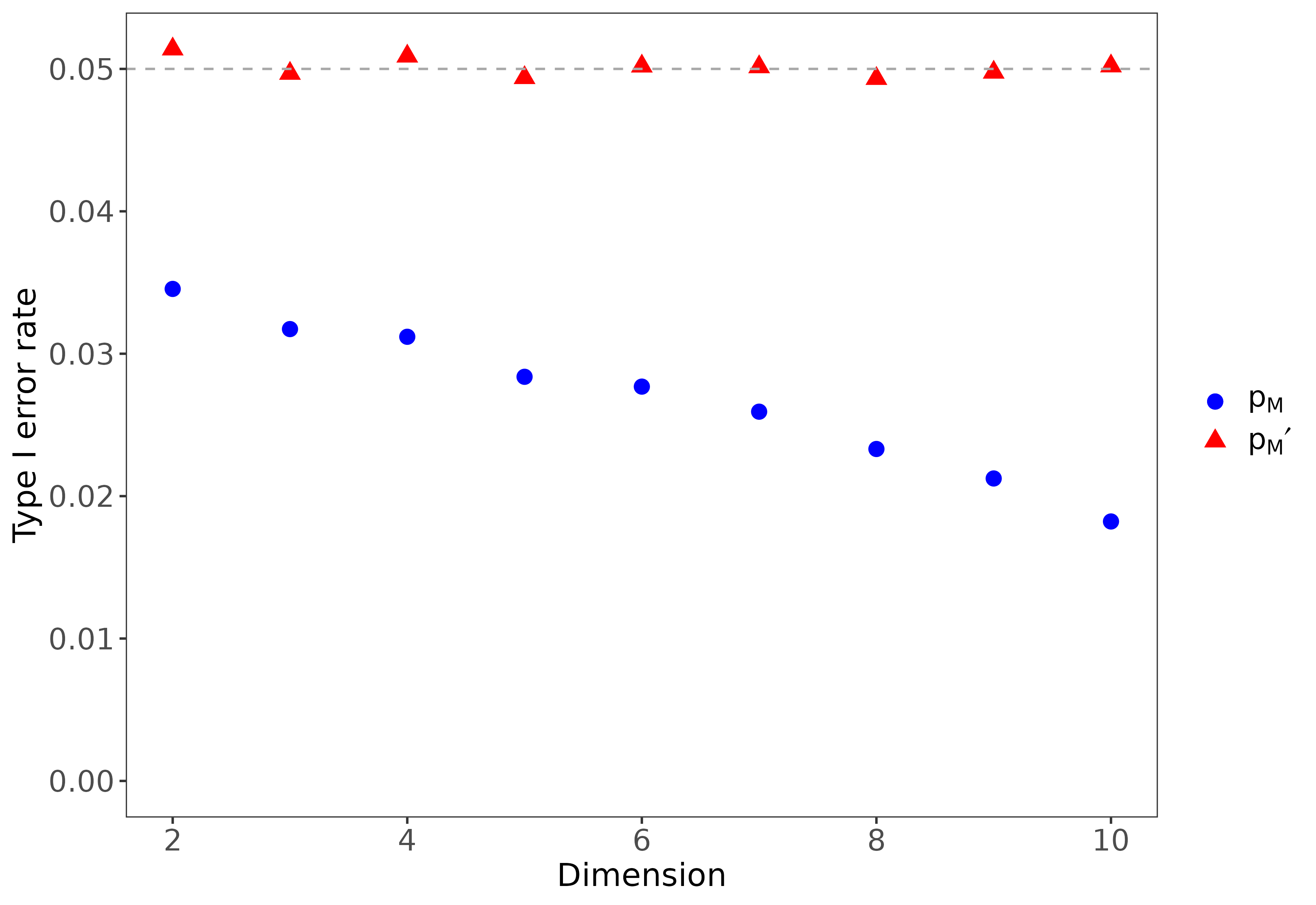
Under certain conditions (see Proposition 2 of Hemerik and Goeman (2018)), the permutation test using the \(p\)-value \(p_{M}\) is exact, which is to say that under the null hypothesis \[\mathbb{P}(p_{m}\leq\alpha)=\alpha \ \forall\alpha\in[0,1].\] However, when there is a nonzero probability of ties in the test statistic, this test can be quite conservative (Hemerik and Goeman 2018). In such cases, the test can be made exact by instead using \[p_{M}'=\frac{\sum_{m=1}^{M}I(\mathcal{D}(\mathbf{Z}_{\sigma_{m}})>\mathcal{D}(\mathbf{Z}))}{1+M}+U\frac{1+\sum_{m=1}^{M}I(\mathcal{D}(\mathbf{Z}_{\sigma_{m}})=\mathcal{D}(\mathbf{Z}))}{1+M}\,,\] where \(U\sim\mathrm{Unif}(0,1)\) (Hoeffding 1952; Hemerik and Goeman 2018). The fact that \(p_{M}'\) is randomized is not inherently problematic, since it is already randomized due to the selection of random permutations (Hemerik and Goeman 2018).
As the test statistic in (3) is discrete, ties are possible, and thus the test using \(p_{M}\) is generally conservative. In high dimensions, ties can become quite prevalent, leading the type I error rate to decrease dramatically (Figure 3). We thus use \(p_{M}'\) as our \(p\)-value instead of \(p_{M}\). As a final remark, we note that if the test statistic is scaled by a constant scalar, \(p_{M}'\) remains unchanged since both indicator functions are invariant under scalar rescaling of \(\mathcal{D}\). Therefore, the outcome of the test does not depend on our choice to use the integer-valued test statistic \(\mathcal{D}\) in (3) over Fasano and Franceschini’s original test statistic \(\mathcal{D}_{0}\) in (2).
3 Package overview
The fasano.franceschini.test package is written primarily in C++, and interfaces with R using Rcpp (Eddelbuettel et al. 2022). The C++ range tree class (Weihs 2020) was based on the description in Berg et al. (2008), including an implementation of fractional cascading. The permutation test is parallelized using RcppParallel (Allaire et al. 2022). The package consists of one function, fasano.franceschini.test, for performing the two-sample Fasano–Franceschini test. The arguments of this function are described below.
S1 and S2: the two samples to compare. Both should be either numeric matrix or data.frame objects with the same number of columns.
nPermute: the number of permutations to use for performing the permutation test. The default is \(100\). If set equal to \(0\), the permutation test is bypassed and only the test statistic is computed.
threads: the number of threads to use when performing the permutation test. The default is one thread. This parameter can also be set to "auto", which uses the value returned by RcppParallel::defaultNumThreads().
seed: an optional seed for the pseudorandom number generator (PRNG) used during the permutation test.
verbose: whether to display a progress bar while performing the permutation test. The default is TRUE. This functionality is only available when threads = 1.
method: an optional character indicating which method to use to compute the test statistic. The two methods are ‘r’ (range tree) and ‘b’ (brute force). Both methods return the same results but may vary in computation speed. If this argument is not passed, the sample sizes and dimension of the data are used to infer which method is likely faster.
The output is an object of the class htest, and consists of the following components:
statistic: the value of the test statistic.
p.value: the permutation test p-value.
method: the name of the test (i.e. ‘Fasano-Franceschini Test’).
data.name: the names of the original data objects.
4 Examples
Here we demonstrate the basic usage and features of the fasano.franceschini.test package. We begin by loading the necessary libraries and setting a seed for reproducibility.
Note that to produce reproducible results, we need to set two seeds: the
set.seed function sets the seed in R, ensuring we draw reproducible
samples; and the seed passed as an argument to the
fasano.franceschini.test function sets the seed for the C++ PRNG,
ensuring we compute reproducible \(p\)-values.
As a first example, we draw two samples from the bivariate standard normal distribution. The Fasano–Franceschini test fails to reject the null hypothesis — that the samples were drawn from the same distribution — at an \(\alpha=0.05\) significance level.
S1 <- mvrnorm(n = 50, mu = c(0, 0), Sigma = diag(2))
S2 <- mvrnorm(n = 75, mu = c(0, 0), Sigma = diag(2))
fasano.franceschini.test(S1, S2, seed = 1, verbose = FALSE)
Fasano-Franceschini Test
data: S1 and S2
D = 1425, p-value = 0.5247We next draw two samples from bivariate normal distributions with identical covariance matrices but different locations. The test rejects the null hypothesis at an \(\alpha=0.05\) significance level.
S3 <- mvrnorm(n = 40, mu = c(0, 0), Sigma = diag(2))
S4 <- mvrnorm(n = 42, mu = c(1, 1), Sigma = diag(2))
fasano.franceschini.test(S3, S4, seed = 2, verbose = FALSE)
Fasano-Franceschini Test
data: S3 and S4
D = 1932, p-value = 0.001832The test can take a while to run when the sample sizes or the dimension of the data are large, in which case it is useful to use multiple threads to speed up computation.
S5 <- mvrnorm(n = 1000, mu = c(1, 3, 5), Sigma = diag(3) + 1)
S6 <- mvrnorm(n = 600, mu = c(1, 3, 5), Sigma = diag(3))
fasano.franceschini.test(S5, S6, seed = 3, threads = 4)
Fasano-Franceschini Test
data: S5 and S6
D = 257800, p-value = 0.0007002Note that the number of threads used does not affect the results. In particular, as long as the same seed is used, the same \(p\)-value is returned for any number of threads.
fasano.franceschini.test(S5, S6, seed = 3, threads = 1)
Fasano-Franceschini Test
data: S5 and S6
D = 257800, p-value = 0.00070025 Comparison with other R packages
In this section, we compare the fasano.franceschini.test package with three other CRAN packages that perform multivariate two-sample goodness-of-fit tests.
5.1 Peacock.test
The Peacock.test package (Xiao 2016) provides functions to compute Peacock’s test statistic (Peacock 1983) in two and three dimensions. As no function is provided to compute \(p\)-values, we cannot directly compare the performance of this package with the fasano.franceschini.test package. However, a treatment of the power of both Peacock and Fasano–Franceschini tests can be found in both the primary literature (Peacock 1983; Fasano and Franceschini 1987) and in a subsequent benchmarking paper (Lopes et al. 2007), which found that the two tests have similar power across a variety of alternatives.
5.2 cramer
The cramer package (Franz 2019) implements the two-sample test described in Baringhaus and Franz (2004), which the authors refer to as the Cramér test. The Cramér test statistic is based on the Euclidean inter-point distances between the two samples, and is given by \[T_{m,n}=\frac{mn}{m+n}\left(\frac{2}{mn}\sum_{i=1}^{m}\sum_{j=1}^{n}\phi\left(\left\lVert\mathbf{X}_{i}-\mathbf{Y}_{j}\right\rVert_{2}^{2}\right)-\frac{1}{m^{2}}\sum_{i,j=1}^{m}\phi\left(\left\lVert\mathbf{X}_{i}-\mathbf{X}_{j}\right\rVert_{2}^{2}\right)-\frac{1}{n^{2}}\sum_{i,j=1}^{n}\phi\left(\left\lVert\mathbf{Y}_{i}-\mathbf{Y}_{j}\right\rVert_{2}^{2}\right)\right)\] for samples \(\mathbf{X}_{1},\dots,\mathbf{X}_{m}\) and \(\mathbf{Y}_{1},\dots,\mathbf{Y}_{n}\). The default kernel function is \(\phi(x)=\sqrt{x}/2\), although several other choices are implemented (see the documentation for more details). Several randomization methods are provided to compute \(p\)-values, including bootstrapping (the default) and a permutation test.
5.3 diproperm
The diproperm package (Allmon et al. 2021) implements the DiProPerm test introduced by Wei et al. (2016). A binary linear classifier is first trained to determine a separating hyperplane between the two samples. The data are then projected onto the normal vector to the hyperplane, and the test statistic is taken to be a univariate statistic of the projected data (by default the absolute difference of means). As in the fasano.franceschini.test package, significance is determined using a permutation test.
5.4 Power comparison
To compare the fasano.franceschini.test package with the cramer and diproperm packages, we performed power analyses using three classes of alternatives: location alternatives, where the means of the marginals are varied; dispersion alternatives, where the variances of the marginals are varied; and copula alternatives, where the marginals remain fixed but the copula joining them is varied.
For location and dispersion alternatives, we used multivariate normal distributions. We denote the \(d\)-dimensional normal distribution with mean \(\boldsymbol\mu\in\mathbb{R}^{d}\) and covariance matrix \(\boldsymbol\Sigma\in\mathbb{R}^{d\times d}\) by \(N_{d}(\boldsymbol\mu,\boldsymbol\Sigma)\), and sample from it using the MASS package (Ripley 2021). The \(d\times d\) identity matrix, which is sometimes used as a covariance matrix, is denoted by \(\mathbf{I}_{d}\). For copula alternatives, we consider the Gaussian copula with correlation matrix \[[\mathbf{P}(\rho)]_{ij}=\begin{cases} \rho,&i\neq j\\ 1,&i=j \end{cases}\] and the Clayton copula with parameter \(\theta\in[-1,\infty)\setminus\{0\}\). We denote the \(d\)-dimensional distribution with standard normal marginals joined by a Gaussian copula with correlation matrix \(\mathbf{P}(\rho)\) by \(G_{d}(\rho)\). We denote the \(d\)-dimensional distribution with standard normal marginals joined by a Clayton copula with parameter \(\theta\) by \(C_{d}(\theta)\). Both distributions are sampled from using the copula package (Hofert et al. 2022). Examples of distributions in each of these four families are shown in Figure 4.
In the following analyses, power was approximated using \(1000\) replications, a significance level of \(\alpha=0.05\) was used, all samples were of size \(40\), and all R functions implementing tests were called using their default arguments. Although we aimed to cover a wide range of distributions in this analysis, absent any theoretical results concerning these three tests, we cannot guarantee that the results here are generalizable to different sampling distributions or sample sizes.
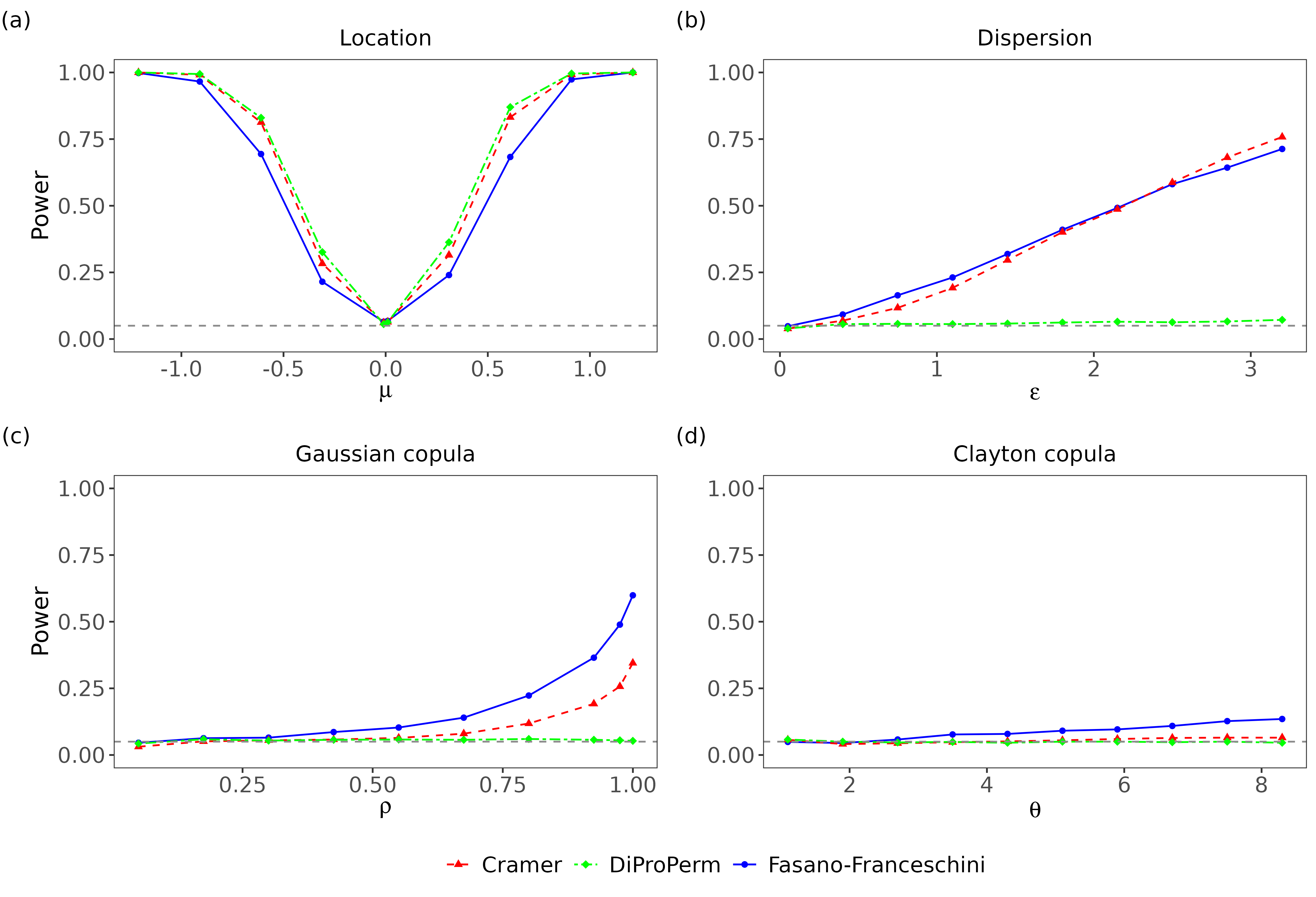
We first examined the power of the tests on various bivariate alternatives (Figure 5). All three tests had similar power across location alternatives, although the Cramér and DiProPerm tests did outperform the Fasano–Franceschini test. Across dispersion alternatives, the Cramér and Fasano–Franceschini tests had very similar powers. On Gaussian copula alternatives, the Fasano–Franceschini test had a consistently higher power than the Cramér test. This was also the case with Clayton copula alternatives, although none of the tests were able to achieve high power. The DiProPerm test was unable to achieve a power above the significance level of \(\alpha=0.05\) on any of the dispersion or copula alternatives. This is likely due to the fact that in these instances, there is significant overlap between the high density regions of the two sampling distributions, making it difficult to find a separating hyperplane between samples drawn from them.
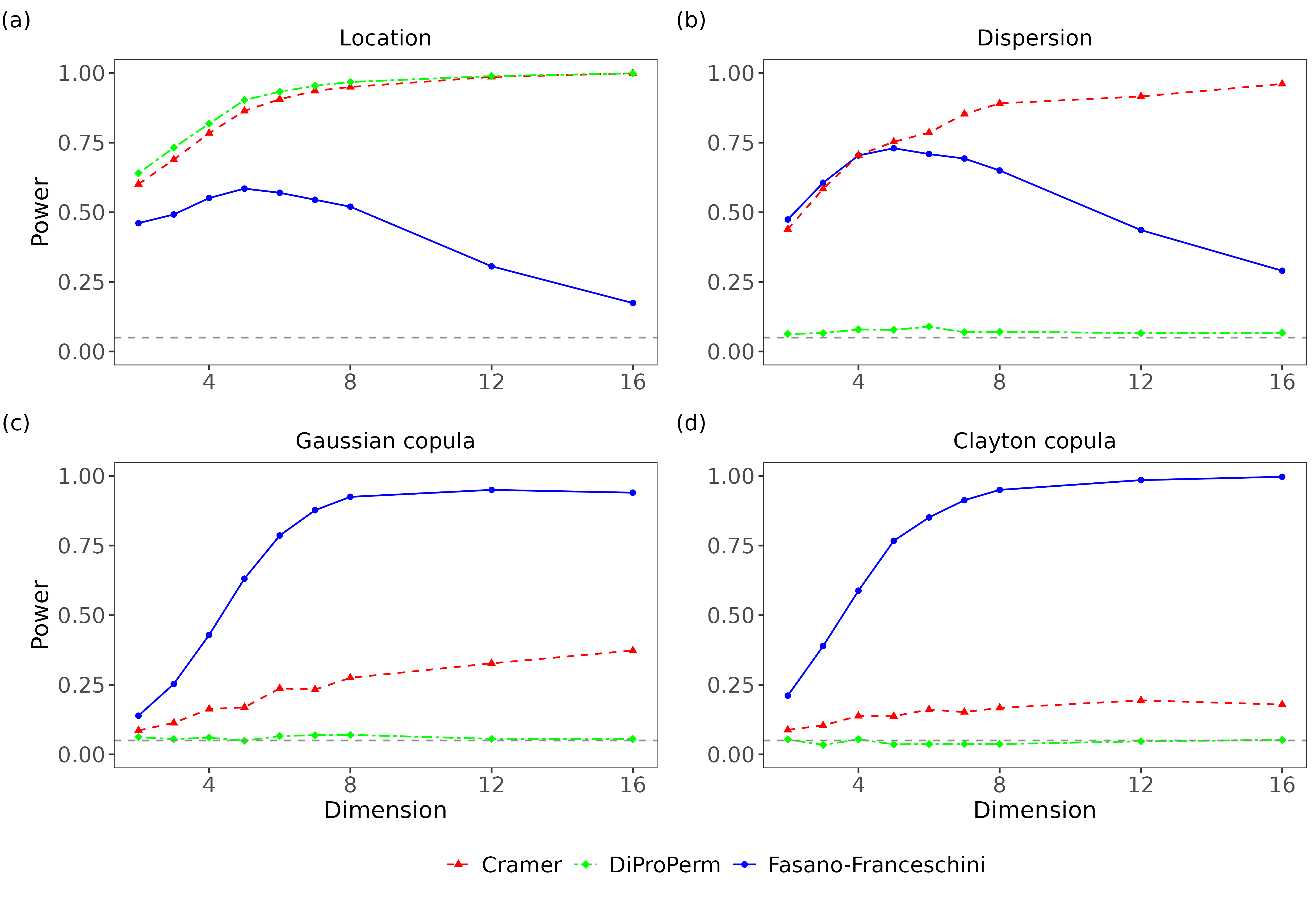
We next examined how the power of the three tests varied when the two sampling distributions were kept fixed but the dimension of the data increased (Figure 6). On the location alternative, the Cramér and DiProPerm tests again outperformed the Fasano–Franceschini test. In particular, for \(d>5\), the Fasano–Franceschini steadily lost power as the dimension increased whereas the other tests gained power. On the dispersion alternative, the Cramér and Fasano–Franceschini tests had nearly identical powers through to \(d=5\), but for higher dimensions the Cramér test consistently outperformed the Fasano–Franceschini test. On the other hand, for both the Gaussian and Clayton copula alternatives the Fasano–Franceschini test had a much higher power than the Cramér test. The DiProPerm test was still unable to attain a power above the significance level on the dispersion alternatives or either of the copula alternatives.
Overall, the Cramér and DiProPerm tests performed better than the Fasano–Franceschini test on location alternatives, especially as dimension increased. On dispersion alternatives, the Fasano–Franceschini and Cramér tests had comparable performance for low dimensions, but the Cramér test maintained a higher power for high dimensions. However, in these cases the marginal distributions differ, and thus a multivariate test is not strictly necessary as univariate tests could be applied to the marginals independently (with a multiple testing correction) to detect differences between the multivariate distributions. On copula alternatives, where a multivariate test is necessary, the Fasano–Franceschini test consistently outperformed both the Cramér and DiProPerm tests. Thus while the Fasano–Franceschini did not achieve the highest power in every case, we believe it to be the best choice as a general purpose multivariate two-sample goodness-of-fit test.
6 Summary
This paper introduces the fasano.franceschini.test package, an R implementation of the multivariate two-sample goodness-of-fit test described by Fasano and Franceschini (1987). We provide users with a computationally efficient test that is applicable to data of any dimension and of any type (continuous, discrete, or mixed), and that demonstrates competitive performance with similar R packages. Complete package documentation and source code are available via the Comprehensive R Archive Network (CRAN) at https://cran.r-project.org/web/packages/fasano.franceschini.test and the package website at https://braunlab-nu.github.io/fasano.franceschini.test.
7 Computational details
The results in this paper were obtained using R 4.2.0 with the packages fasano.franceschini.test 2.2.1, diproperm 0.2.0, cramer 0.9-3, MASS 7.3-60, copula 1.1-2, and microbenchmark 1.4.10 (Mersmann 2023). Plots were generated using ggplot2 3.4.2 (Wickham et al. 2023) and patchwork 1.1.1 (Pedersen 2020). All computations were done using the Quest high performance computing facility at Northwestern University.
8 Acknowledgments
This research was supported in part through the computational resources and staff contributions provided for the Quest high performance computing facility at Northwestern University which is jointly supported by the Office of the Provost, the Office for Research, and Northwestern University Information Technology. Funding for this work was provided by NIH/NIA R01AG068579, Simons Foundation 597491-RWC01, and NSF 1764421-01.
8.1 Supplementary materials
Supplementary materials are available in addition to this article. It can be downloaded at RJ-2023-067.zip